Exploring Feature Importances with MMoCHi
Authors: Daniel Caron and William Specht
In this notebook, we will evaluate individual features for their importance during random forest classification. This can provide insight into how the random forests are performing and identify novel transcriptomic and proteomic markers of cell subsets.
Exploring Feature importances
What are feature importances and why use them?
Unlike some supervised classifiers, which rely on strict feature selection or dimensionally reduced feature sets, random forests perform well with high-dimensional data. When training decision trees, features are selected for their ability to reduce impurity at each branch. To reduce overfitting, random forests average over multiple decision trees trained under similar conditions. This naturally lends itself well to ranking features based on their importance for classification. Although there are many methods to calculate feature importance, here we use scikit-learn’s implementation of impurity-based feature_importances where importance is calculated from the mean decrease in Gini impurity across the trees in a forest. A ranking of these importances can then be generated for each classification layer providing insight into differences between subsets at each level of the classifier. Note that other methods to calculate important features, including permutation-based methods, tend to be much slower to calculate, but could also be used.
Feature importances can serve a few purposes. First, they can be used to understand how the random forest is classifying cell types and may reveal why specific events are or are not being labeled correctly. While well-performing classifiers will have high feature importances for highly expressed cell type markers, poorly performing classifiers may give high feature importance to batch-specific artifacts. If this is the case, the training data or feature set given to the random forest for
classification can be altered to improve performance. Alternatively, if cell type markers are given a high performance but classification is still sub-par, random forest hyperparameters (with the clf_kwargs argument in mmc.Hierarchy.add_classification()) can be altered to increase fit and improve performance. More information on random forest hyperparameters here.
Another useful application of feature importances is as a discovery tool for novel cell type markers. Newly identified markers may inform high-confidence thresholding and fluorescence-based gating strategies. For this application, it’s worth noting that feature importances are not associated with individual subsets, so one must take care during interpretation of highly important features, especially in multiclass scenarios. To associate features with a subset, we suggest using differential expression analysis. By providing a window into profiles of our cell types, features identified may also pave the way for new avenues of study, similar to differential expression. See our paper at Cell Reports Methods for more details.
Import packages
[7]:
import anndata
import mmochi as mmc
import os
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 150
mmc.log_to_file('mmochi_feature_importance')
Load in hierarchy used for classification and classified data
Run Integrated Classification First!
This tutorial builds off of the Integrated Classification tutorial, and uses the trained MMoCHi classifier and classified AnnData object saved during that tutorial.
Let’s load in the previously saved AnnData and MMoCHi Hierarchy objects:
[8]:
assert os.path.isfile('data/classified_events.h5ad') & os.path.isfile('data/IntegratedClassifier.hierarchy'), \
'Objects not found. Run the Integrated Classification tutorial to generate them!'
adata = anndata.read_h5ad('data/classified_events.h5ad')
h = mmc.Hierarchy(load='data/IntegratedClassifier')
h.display(True)
Loading classifier from data/IntegratedClassifier...
Loaded data/IntegratedClassifier.hierarchy
Once the random forest classifiers have been trained and stored in the hierarchy, feature importances can be extracted as a list using mmc.feature_importances(), which returns a DataFrame of all features sorted by importance for the specified level. Within MMoCHi, features are labeled by their modality (separated by '_mod_'). You can see here that for lymphocyte subsets, there are many genes whose expression is highly important for subset identification:
[9]:
mmc.feature_importances(h, 'Lymphoid').head(25)
[9]:
| Feature | Importance | |
|---|---|---|
| 0 | MZB1_mod_gex | 0.028209 |
| 1 | ITM2C_mod_gex | 0.020467 |
| 2 | HSP90B1_mod_gex | 0.017774 |
| 3 | SSR3_mod_gex | 0.014550 |
| 4 | RPS27_mod_gex | 0.013955 |
| 5 | RPL19_mod_gex | 0.013943 |
| 6 | SEC61B_mod_gex | 0.013772 |
| 7 | HLA-DRB1_mod_gex | 0.013506 |
| 8 | FKBP11_mod_gex | 0.011392 |
| 9 | FOS_mod_gex | 0.011151 |
| 10 | RPL11_mod_gex | 0.010829 |
| 11 | TYROBP_mod_gex | 0.010296 |
| 12 | TXNDC11_mod_gex | 0.010145 |
| 13 | ST6GALNAC4_mod_gex | 0.009714 |
| 14 | EIF1_mod_gex | 0.009353 |
| 15 | DERL1_mod_gex | 0.008687 |
| 16 | MAN1A1_mod_gex | 0.008624 |
| 17 | GSPT1_mod_gex | 0.008461 |
| 18 | RPS23_mod_gex | 0.008381 |
| 19 | RPL34_mod_gex | 0.008015 |
| 20 | RPN1_mod_gex | 0.007977 |
| 21 | HLA-DQB1_mod_gex | 0.007746 |
| 22 | CD45RA_mod_landmark_protein | 0.007548 |
| 23 | JCHAIN_mod_gex | 0.007463 |
| 24 | RPL30_mod_gex | 0.007312 |
If you are interested in focusing on proteins and protein coding transcript markers, you may want to limit classification only protein coding genes. Additionally, limiting to only protein coding genes may help to remove some sequencing artifacts, and improve classification performance. This can be accomplished by removing these genes prior to classification, or using the limit argument in mmc.classify. See docs for more details.
On other levels, such as CD4+ vs CD8+ T cells, you can see various proteins played a more important role in cell type classification. Note that the much higher values for importance here are in part due to the hyperparameters used to train the random forest at this level (see the Hierarchy Design tutorial for more details).
[10]:
mmc.feature_importances(h, 'CD4_CD8').head(25)
[10]:
| Feature | Importance | |
|---|---|---|
| 0 | CD8a_mod_landmark_protein | 0.049247 |
| 1 | CD8A_mod_gex | 0.041444 |
| 2 | CD4_mod_landmark_protein | 0.041034 |
| 3 | CD8B_mod_gex | 0.028655 |
| 4 | CD14_mod_landmark_protein | 0.019218 |
| 5 | NKG7_mod_gex | 0.015018 |
| 6 | CD4_mod_gex | 0.011821 |
| 7 | CTSW_mod_gex | 0.010518 |
| 8 | CD25_mod_landmark_protein | 0.010272 |
| 9 | HCST_mod_gex | 0.009794 |
| 10 | CCL5_mod_gex | 0.008704 |
| 11 | CD40LG_mod_gex | 0.006574 |
| 12 | MT-CO3_mod_gex | 0.006571 |
| 13 | RPS27_mod_gex | 0.006326 |
| 14 | DUSP2_mod_gex | 0.006306 |
| 15 | CD45RA_mod_landmark_protein | 0.006077 |
| 16 | LINC02446_mod_gex | 0.005983 |
| 17 | CD3_mod_landmark_protein | 0.005397 |
| 18 | CST7_mod_gex | 0.005114 |
| 19 | GZMA_mod_gex | 0.004686 |
| 20 | GZMK_mod_gex | 0.004410 |
| 21 | RPL30_mod_gex | 0.004340 |
| 22 | MYL6_mod_gex | 0.003844 |
| 23 | GZMM_mod_gex | 0.003840 |
| 24 | FHIT_mod_gex | 0.003468 |
Visualization to evaluate classification
The plotting function below displays the top 25 most important features for the specified classification layer(s) in violin plots. These plots highlight which subsets express the most important features. By default, these plots group events by their high-confidence label and their predicted classification. This is incredibly useful for exploring discrepancies between high-confidence thresholding and classification, or for understanding performance on cells that were not high-confidence
thresholded. For example, here we can identify that in the Lymphoid classifier, many of the events not labeled by high-confidence thresholding, but labeled NK/ILC ('? -> NK_ILC') actually expressed CD3 protein. Although this only represents ~200 events, it suggests there is room for improvement in the high-confidence thresholding or the hierarchy design. Note that these plots also display the expression of these markers on cells not included at this classification level ('nan -> nan')
for reference.
[11]:
mmc.plot_important_features(adata, 'Lymphoid', h)
... storing 'hc -> class' as categorical
WARNING: dendrogram data not found (using key=dendrogram_hc -> class). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
/home/ubuntu/miniconda3/envs/mmochi/lib/python3.11/site-packages/scanpy/tools/_utils.py:40: UserWarning: You’re trying to run this on 33538 dimensions of `.X`, if you really want this, set `use_rep='X'`.
Falling back to preprocessing with `sc.pp.pca` and default params.
warnings.warn(
WARNING: dendrogram data not found (using key=dendrogram_hc -> class). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
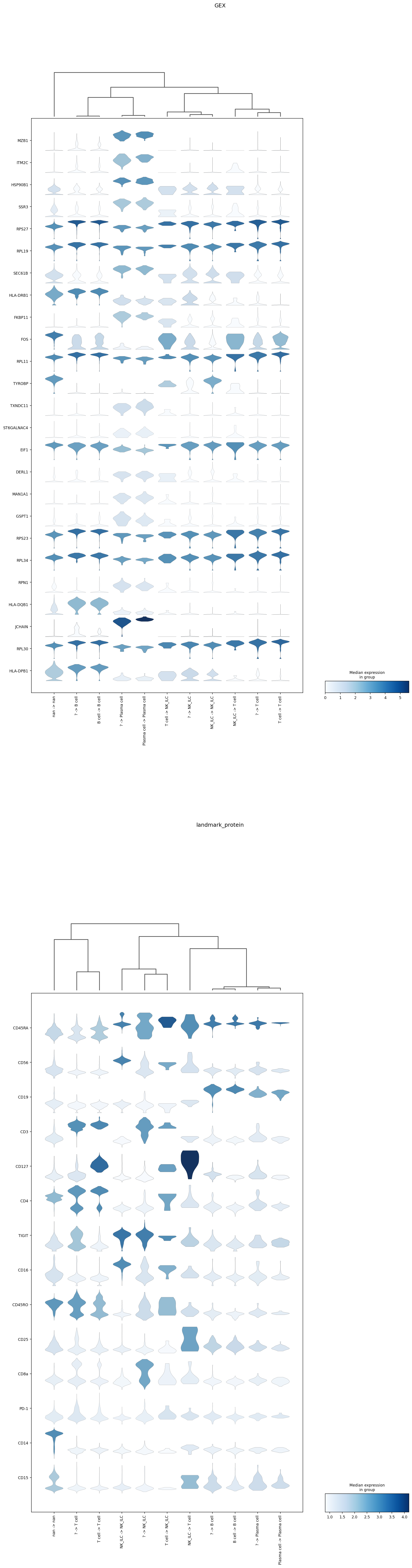
To best compare expression levels between classified subsets, ‘classification’ can be passed as an argument to display all subsets at an individual classification level.
[12]:
mask = (~adata.obsm['lin']['CD4_CD8_hc'].isin(['nan']))
mmc.plot_important_features(adata[mask].copy(), ['CD4_CD8'], h, reference = 'classification')
WARNING: Dendrogram not added. Dendrogram is added only when the number of categories to plot > 2
WARNING: Dendrogram not added. Dendrogram is added only when the number of categories to plot > 2
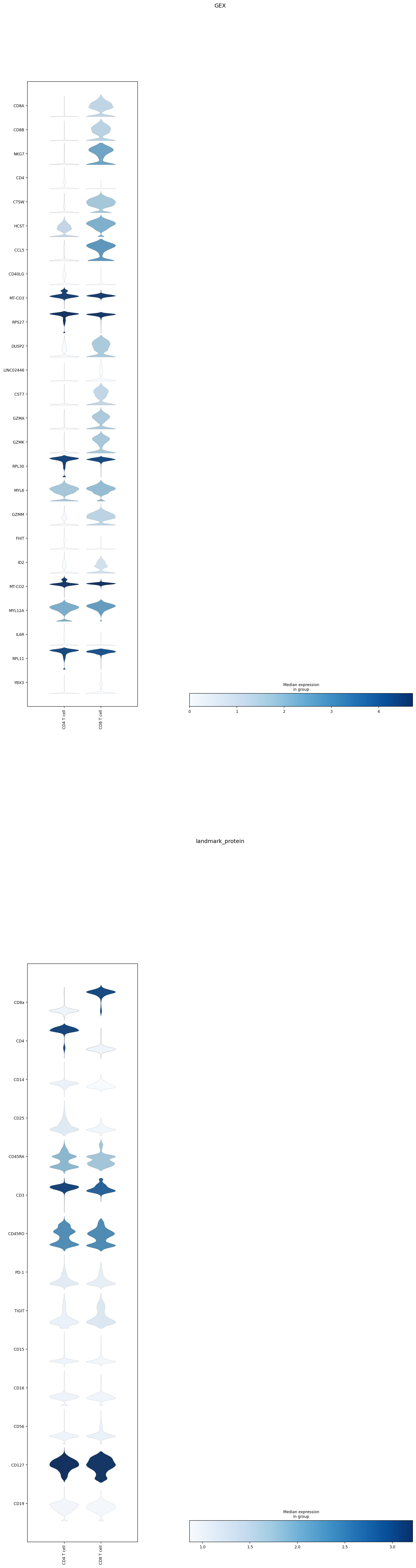
Great!
You can now gain more insight into the decisions your classifier makes, and use feature importances to identify cell type markers